My bachelor's research internship with the focus on conducting a literature study on existing possibilities within the domain of reinforcement learning and autonomous driving.
Race to the Future
Reinforcement Learning for Quick Autonomous Driving on Unknown Racetracks
Simon Wilmots - PXL DIGITAL 2022 (AI & Robotics)

This is me at the Race to the Future competition, following our remote-controlled racecar on its first attempt on the track.
Acknowledgment
As I near the end of my professional bachelor's degree in applied computer science with a specialization in AI & Robotics, it is astonishing how much of an impact higher education has made over the previous three years.
I want to express my gratitude to my parents, friends, and fellow PXL-Digital students, as well as the students who participated in the research project, for providing me with this once-in-a-lifetime opportunity.
Abstract
The potential for reinforcement learning in autonomous driving is examined in this study by a student participating in an internship. Here, the various parts of autonomous driving systems are examined first, and then the various reinforcement learning approaches are explored.
One must take a step back before applying a reinforcement learning system to an RC car. First, it's important to look at the components that autonomous driving vehicles are made of. These are typically the sensory perceptions, like sensors or cameras, of the system that take particular measurements. The car begins to try to drive itself based on these readings. In this study, the steering is kept quite straightforward. Specifically, accelerating, braking, and steering in a particular direction.
We can now look at what goes into constructing an algorithm after conducting in-depth research on the parts of autonomous RC cars. Here, the various reinforcement learning approaches are also cited and contrasted.
It's time to put a reinforcement learning algorithm into practice when all the theoretical research has been completed. The various reinforcement learning algorithms contained in the ROS package "openai ros" are evaluated in this final study.
Ultimately, a fellow student will come to a conclusion about how to make an RC car drive autonomously based on his studies; with computer vision or machine learning. It is time to make the RC car ready to win the race once the best technique has been chosen and put into effect.
List of Abbreviations
| Abbreviation | Meaning | Explanation | | ------------- | ------------------------------------- | --------------------------------------------------------------------------------------------------------------| | AR | Augmented Reality | Making the real world interactive with digital information or objects | | API | Application Programming Interface | A connection between software parts to share data in a distributed way | | BGR | Blue Green Red | Alternative representations of the RGB color model. | | CNN | Convolutional Neural Network | A neural network specializing in image processing | | CV | Computer Vision | Getting computers to interpret the visual world | | DC-DC | Direct Current - Direct Current | Unidirectional flow of electric charge | | HSV | Hue Saturation Value | Alternative representations of the RGB color model. | | IoT | Internet of Things | Devices that exchange data with other devices and systems over the internet or other communication networks. | | ML | Machine Learning | A domain within artificial intelligence to predict outcomes without being explicitly programmed to do so. | | PiComm | (Raspberry) Pi Communicator | A tool developed to replace the RC car remote control | | PWM | Pulse Width Modulation | Adjusting the power of an electrical signal. | | RC | Remote Controlled | / | | RGB | Red Green Blue | Het meest gebruikte kleurenmodel | | RL | Reinforcement Learning | Training method based on rewarding desired behavior and/or punishing undesired behavior. | | ROS | Robot Operating System | Opensource robotics framework | | RPi | Raspberry Pi | The onboard computer used on the RC car | | RTTF | Race to the Future | A race for autonomous cars | | SLAM | Simultaneous localization and mapping | The ability of a robot to locate itself and simultaneously create a map of its surroundings | | VR | Virtual Reality | Technology that simulates 3D environments in which a user can navigate and walk around. | | VS | Versus | Comparative |
Introduction
In recent years, the concept of "artificial intelligence" has gained enormous popularity. This is because AI can now be employed more practically than ever before. Better hardware and software are also accessible for the development of AI.
At least one AI-related project is now underway at many cutting-edge businesses. Tesla Motors is one of the most creative businesses, renowned for its superiority in the field of AI. In order to honor this company's accomplishments in the field of autonomous driving systems, some implementations made during the internship elaboration have been given product names.
PXL-research Research's section, Smart-ICT, has been studying the autonomous movement of mobile robots for a while. Robots will be used in the experiments to carry out one or more difficult tasks in an uncharted area. The yearly event "Race to the Future" was born out of these investigations into the development of mobile and autonomous robots. a contest to see whose artificial intelligence can get self-driving automobiles around a circuit the fastest.
The primary goal is to have the remote-controlled automobile travel as quickly as possible on an uncharted circuit. Each team receives a set of hardware and software to accomplish this. This kit includes a modified remote-control car with a built-in computer and camera. The onboard computer's artificial intelligence component is then developed and put into use by each team.
The "Race to the Future" internship program at PXL Smart-ICT goes beyond taking part in the race. Actually, the research on self-driving RC cars is divided into two separate programs.
On the one hand, a PXL Smart-ICT student researches and examines the potential applications of reinforcement learning in autonomous vehicle systems. Here, research is first conducted on the many parts of autonomous driving systems before moving on to the various reinforcement learning approaches.
On the other hand, a fellow student analyses the variations between machine learning and more conventional computer vision. This study was made possible by the fact that in every race, vehicles controlled by computer vision outperformed vehicles controlled by machine learning.
I. Elaboration of the Internship Assignment
The first part of the internship elaboration consists of the parameters that the research team and the participants of the race must take into account at all times. These are constraints imposed by the organization of the race or from College PXL itself.
Information required to comprehend some of the research section's details is provided in the second section.
General Information
Race to the Future regulations
The Race to the Future regulations states that one lap on the track should last no more than five minutes [1]. This means that the speed parameter on the car must be adjusted appropriately. This s important to cover the track as fast as possible, while the length and shape of the track are not known in advance. If an RC car has a collision with the track edge and needs to be picked up, the team will receive fifteen seconds of penalty time. It has also been mentioned that all parts that are in the basic RC car may not be modified. So this does not include the onboard computer or the extra battery. For example, more electrical current can be given to the engine so that it will run faster, but this is strictly prohibited.
Hardware kit
The hardware kit is the basis for getting the car ready for use. The package contains the standard RC car, called PirateShooter from the manufacturer T2M, and the accompanying remote control. Also included in the package is a Raspberry Pi with a camera, an Arduino Pro Micro, a PWM motor chip, and a DC-DC power chip.
The Raspberry Pi is the onboard computer or brain of the car and performs all the calculations. The Arduino receives all the signals from the remote control and sends them to the onboard computer. The Pulse Width Modulation or PWM motor chip drives the motor based on the signals received from the onboard computer. Finally, the Direct Current-Direct Current or DC-DC power chip provides the proper power supply to all the chips on the custom RC car. The power supply comes from the battery included with the standard car.

The bottle was not included in the hardware kit :)
Software framework
The software provided consists of a framework for drivers to software control the car and retrieve the camera images. The framework is developed using the Python programming language and can also record and store training data for the AI. The software package provided is not a requirement and may be modified or replaced with self-written software. [1]
ROS Kinetic Kame
The software used to control the car was developed in 'ROS Kinetic Kame'. ROS, which stands for Robot Operating System, is not an actual operating system as the name implies, but rather a software framework. This is a collection of software code written by open-source developers to solve difficult problems, such as making complex mathematical calculations, driving an RC car, or making data processing easier.
ROS Kinetic is the tenth release of the ROS distribution. The Kinetic distribution was released on May 23, 2016, and was supported through April 2021. Since the original control software from the first edition of the Race to the Future event uses this distribution, the choice was made to continue on the already existing software and not to change distributions.
PiComm
PiComm is a software tool originally developed by the Race to the Future founders in a web framework for Python called Flask. The focus of the tool is to wirelessly execute remote commands on the onboard computer. These commands were initially only for switching between manual driving and computer vision or artificial intelligence.
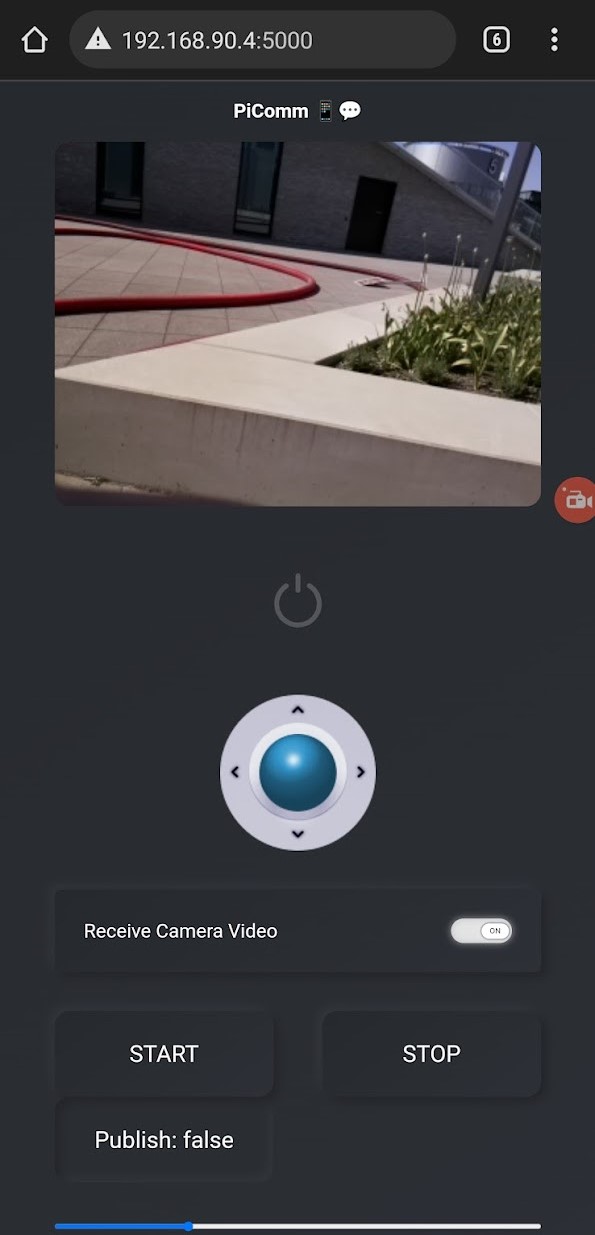
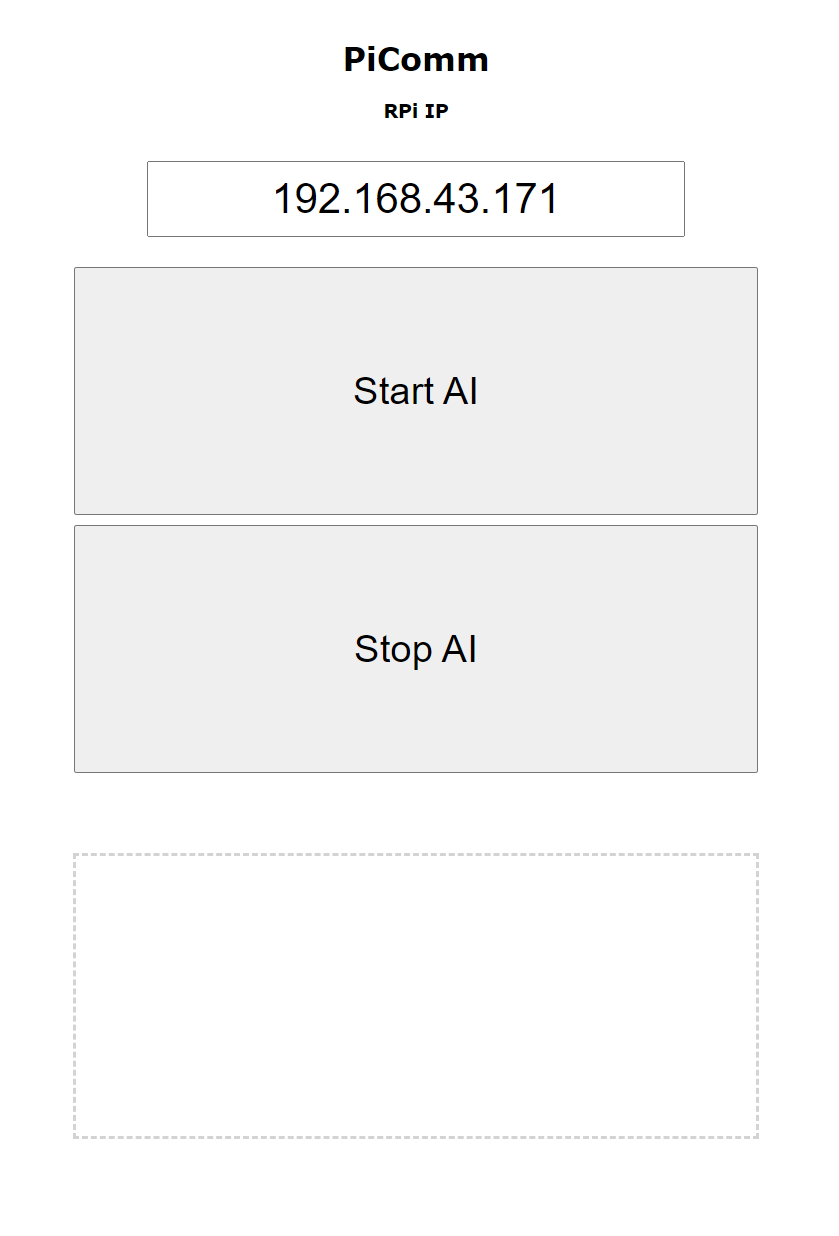
The PiComm has had quite a metamorphosis from the internship team. They have ensured that the car can also be controlled using a digital joystick. This digital joystick has completely replaced the real, physical, remote control. New buttons have also been added to the PiComm. The buttons replace the original remote control emergency stop and also add more security. For example, all signals going to the RC car can be blocked to prevent artificial intelligence from doing unforeseen things.
The figure on the right compares the user interface of the PiComm tool. The left figure is what the tool looked like before the start of the internship. The right figure is after the metamorphosis of the internship team.
Flask takes care of setting up a web server on the onboard computer. Using the board computer's IP address, we can find the PiComm web interface through a browser from any computer, on the same network as the board computer.
The operation of the RC car on the PiComm is designed to be as user-friendly and simple as possible. The closest image shows what the final user interface looks like.
Computer Vision & Race track detection
The ROS node that processes the computer vision, called detector_node, listens to the camera's ROS topic. When a new image comes in, the node starts detecting the path based on a number of steps.
First, the image coming directly from the camera is bilaterally filtered. A Bilateral filter is a filter to remove mainly noise from the image. It replaces the intensity of each pixel with a weighted average of intensity values of pixels. [3] After applying the filter, it appears as if a blur filter has been applied to the image.
Then the color values, from the bilaterally filtered image, are converted to another color palette. In one filter, the color values are converted from BGR to HSV. In the other filter, the color values are converted to LAB. Images in OpenCV use the same RGB color values by default but in a different order namely BGR (Blue, Green, Red instead of Red, Green, Blue). The image is converted to HSV (Hue Saturation Value) and LAB (CIELAB color code [4]) because the edge of the race track is much more visible than in a normal RGB/BGR context.
Next, the range of HSV and LAB values that best match the edge of the race track is stored in a variable. After this, a mask is created, of both, so that only the values within this range are stored. A mask can be used later to crop out the original image, leaving only the edge of the racetrack.
Finally, the two masks are merged using the bitwise operator 'OR'. This is done by merging the binary representation, the white pixels are represented as the number 1 and the black pixels as the number 0, of the masks. In short, the operator retains all the white pixels from both images and fills in the rest as black pixels. [5] This forms the final mask, which is used to recognize the edge of the racetrack.


The edges of the physical raceway are not always consistent. It may perhaps occur that there is a gap between a transition of two tubes. This is something that computer vision must also be able to deal with.
Connecting disjointed tubes was accomplished by connecting the extreme points of the tubes to each other.
Autonomous driving on the race track
Telescope
Telescope is the first computer vision algorithm developed by the internship team. The name Telescope was chosen to stay within the same theme as the team name Starship. In fact, a telescope also uses a lens just like the camera of Starship's RC car.
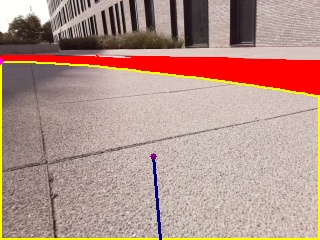
The steering direction and speed are calculated in this algorithm using the blue line and the pink point shown in the figure. The line connects the center of the road (purple point) with the center of the bottom of the image. The speed is calculated from the length of the blue line and varies based on the location of the road.
The pink point (upper left corner of the road detection) visualizes the farthest point on the road. The blue line and pink point make a good estimate of which way the race track is turning and are used to calculate the steering angle.
Autopilot
The latest implementation is Autopilot. This is named after the control software of the autonomous cars at Tesla Motors. The algorithm is a combination of Telescope and an improved implementation of the driving module.
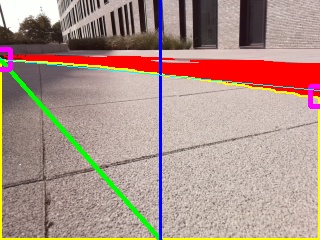
Autopilot uses the road detection explained in Detecting the race track instead of the one in the software framework of Race to the Future.
A second change with the software framework is that Autopilot is able to recover itself from a possible error using the thin light blue line connecting the pink squares. For example, other teams have to pick up the RC car when it collides with the edge and put it back at the previous checkpoint. This will give the team at least fifteen seconds of additional penalty time. Autopilot is prepared for this and, in the event of contact with the edge, will reverse a few meters and place itself back correctly on the track.
A third and final difference is in the calculation of the steering direction. The steering angle from the driving module is now converted to a percentage that represents the steering intensity of the angle.
This percentage (a number between 0 and 1) is entered in the function below as 𝑥 and returns a better steering angle for navigating the track.
𝑓(𝑥)= −1(1+𝑥)7+1
𝑓(0.15)= −1(1+0.15)7+1
𝑓(0.15) ≈0.62
The function is the result of many attempts with a lot of trial and error. In the end, this formula has the best result for the RC car.
Autopilot has been used in the participation in Race to the Future 2022 but due to a time constraint, no speed optimization has been provided and this algorithm, like the software framework, is going to drive at a constant speed along the route.
Unity Simulation

Reinforcement learning, a domain within machine learning, requires a high number of interactions with the environment. Teaching a given task to a robot is done with a great deal of trial and error and will learn to perform the task based on decisions made using rewards and punishments. The jargon within reinforcement learning refers to this robot, which is trained, as the agent. From now on, for clarity and consistency of research, the person or robot in question will only be referred to as an agent, ML-, RL-agent, or some such variant.
Since the agent has to do thousands, tens of thousands, or perhaps hundreds of thousands of interactions with the environment, this is almost impossible to achieve in a real-world context. Therefore, programmatic training must be done in a simulation environment. In this, the agent can be immediately corrected for every mistake or rewarded for every good action. Within the environment of a simulation, it is possible to play with the environment parameters. For example, it is possible to change the texture of the ground from paving stones to, for example, grass or cobblestones. It is also possible to play with different angles of light or even light colors. The possibilities are endless within a simulation. More about changing the environment can be found in Dynamic Environments. First, the construction of the simulation world is thoroughly explained.
Generating trajectories with the Bézier curve
The race track in the simulation world should have a strong resemblance to the physical path. The path is generated using an asset from the Unity Asset Store called Bézier Path Creator. As can be inferred from the name, this is a way to create paths based on the Bézier curve. The Bézier curve is a way of creating curves and turns using a mathematical formula. [6], [7]

Dynamic environments
In the introductory excerpt of the Unity simulation it was mentioned that in simulations, the environment can be changed programmatically based on the environment parameters. That is, it is possible to change the matter of the race track, the light color, or the light incidence so that the RC car can navigate itself in any possible state of the race track. The track edge is also changeable between a number of different shades of red. The figures below show some possible surfaces in the simulation environment.

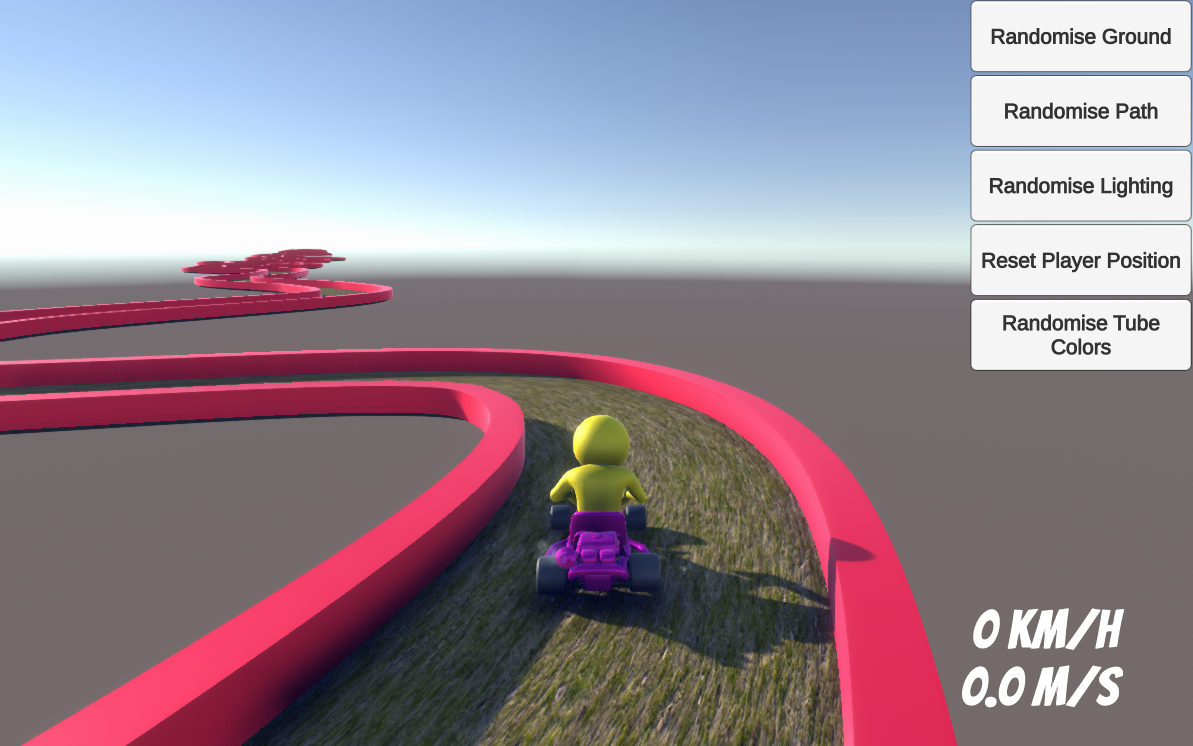
While training the machine learning algorithm, the surface, light incidence, and light color will change based on an interval.
It is also possible to manually change the parameters in the simulation environment by pressing one of the buttons in the user interface.
Reinforcement Learning
This section discusses the reinforcement learning implementation, also known as the RL module. The literature review and explanations are discussed in part II of the study.
OpenAI Gym
OpenAI Gym is an open-source Python library to develop and compare reinforcement learning algorithms. Using the OpenAI Gym API, communication between learning algorithms and their environments is facilitated. The library also provides a large number of environments that are ready to be used by a learning algorithm. On the other hand, during the internship assignment, tasks that are not part of the Gym package must be performed. Fortunately, the OpenAI Gym is flexible enough to do this by creating a custom environment based on the API. [8]
ROS & OpenAI Gym
The OpenAI Gym normally communicates with the reinforcement learning algorithm via the OpenAI Gym API. However, to stay as close to reality as possible, Unity uses an implementation of ROS to drive the car. Therefore, the communication between the RL algorithm and the OpenAI Gym is also via ROS.
The connection is accomplished with the Python library roslibpy. This is the same library as on PiComm's Flask server in 3.4.1 Flask & Javascript.
Conditions and elements of the environment
During the startup of the custom OpenAI Gym, a series of environmental conditions are provided to allow the algorithm to perform the tasks correctly. Namely, the agent is given a predetermined number of attempts to try to cover as much distance as possible and keep the reward as high as possible. Each attempt stops if there is a collision with the trajectory edge. There are also only three possible actions that the agent can predict namely: steering left, steering right, and driving straight. After the environment is set up, the agent can be released into the simulation world. The implemented learning algorithm is Deep Q-Learning. The reason this particular algorithm was chosen is clarified in the literature study.
Deep Q-Learning (DQN)
Deep Q-Learning is a deep neural network implemented on top of the Q-Learning algorithm. Again, the full comparison between the different algorithms is made in the study.
A hyperparameter is a parameter used in machine learning whose value for training an algorithm is determined before learning. This value may and cannot be adjusted during learning. A normal parameter within machine learning is a value that does get adjusted during the learning process. It is important to choose the right hyperparameters for training starts because it has a great impact on the performance of a prediction model.
The main hyperparameters of the algorithm used during the internship assignment are shown in the table below.
| Name | Default value | Explanation | | ------------- | -------------- | ---------------------------------------------------------------------------------------| | Epsilon ϵ (or exploration rate) | 1.0 | The probability that the algorithm will explore a random action to learn from it | | Epsilon decay | 0.995 | A number multiplied by epsilon to gradually lower the exploration rate | | Alpha α (or learning rate) | 1.0 | The number that decides how much to adjust the weights in the neural network | | batch_size | 64 | The number of training iterations in one drive attempt on the route | | do_train | True | A value that contents whether the algorithm should train or use an existing model | | num_episodes | 500 | The number of driving attempts on the route | | num_actions | 3 | The number of actions an agent can perform |
When the algorithm starts learning, the exploration value (epsilon ϵ) starts at the maximum (1) and will gradually decrease to the minimum (0.1) based on the epsilon decay. Using the formula below, it is possible to calculate at which row attempt the epsilon value is at the minimum and thus the algorithm has the least chance of exploring. The number of maturation attempts is represented as 𝑥. [9]
𝛜𝒎𝒂𝒙⋅ 𝛜𝒅𝒆𝒄𝒂𝒚𝒙 = 𝛜𝒎𝒊𝒏
𝟏⋅ 𝟎.𝟗𝟗𝟓𝒙 = 𝟎.𝟏
𝒙 ≈𝟒𝟓𝟗
To know what the exploration value is for a particular drive attempt, 𝑥 must be given the value of the current drive attempt. The formula below calculates the exploration value for row attempt 75.
𝛜currentattempt=𝛜𝒎𝒂𝒙⋅ 𝛜𝒅𝒆𝒄𝒂𝒚𝒙= 𝟏 ⋅𝟎.𝟗𝟗𝟓𝟕𝟓≈𝟎.𝟔𝟗
Layers in the convolutional neural network
In a Deep Q-Network (DQN), a neural network is implemented on top of the Q-learning algorithm. DQNs can also learn directly from high-dimensional sensory input such as images and/or videos. [10] A neural network that can process images is also referred to as a convolutional neural network or CNN for short.
The first block of layers in the neural network is the convolutional layer along with a Batch normalization and a max pooling layer. The convolutional layer places a filter on the image to extract the most important visual elements. The result after this layer is also called a feature or activation map. After this, the output of the convolutional layer goes through a Batch normalization layer to normalize the values. The last layer of this block in the CNN is the max pooling layer. This reduces a feature map by taking the maximum values of each visual element. The reduced feature map is then plugged into the same type of block twice more to reduce the size of the image and model.
After the three convolutional blocks, the output is smoothed into a flattening layer. This layer turns the multidimensional image or feature map into a one-dimensional feature map. This allows an image to easily flow over to subsequent layers. The output of the flattening layer passes to the hidden dense layers. These have a number of different nicknames such as fully connected layers, hidden layers, and dense layers. The name hidden means that the values are not known during the training process and it is kind of a black box. The purpose of the fully connected layers is to classify the image to predict the correct action for the agent.
The last layer is an optimization layer and is going to adjust the weights from the fully connected dense layers so that the algorithm will make fewer errors.
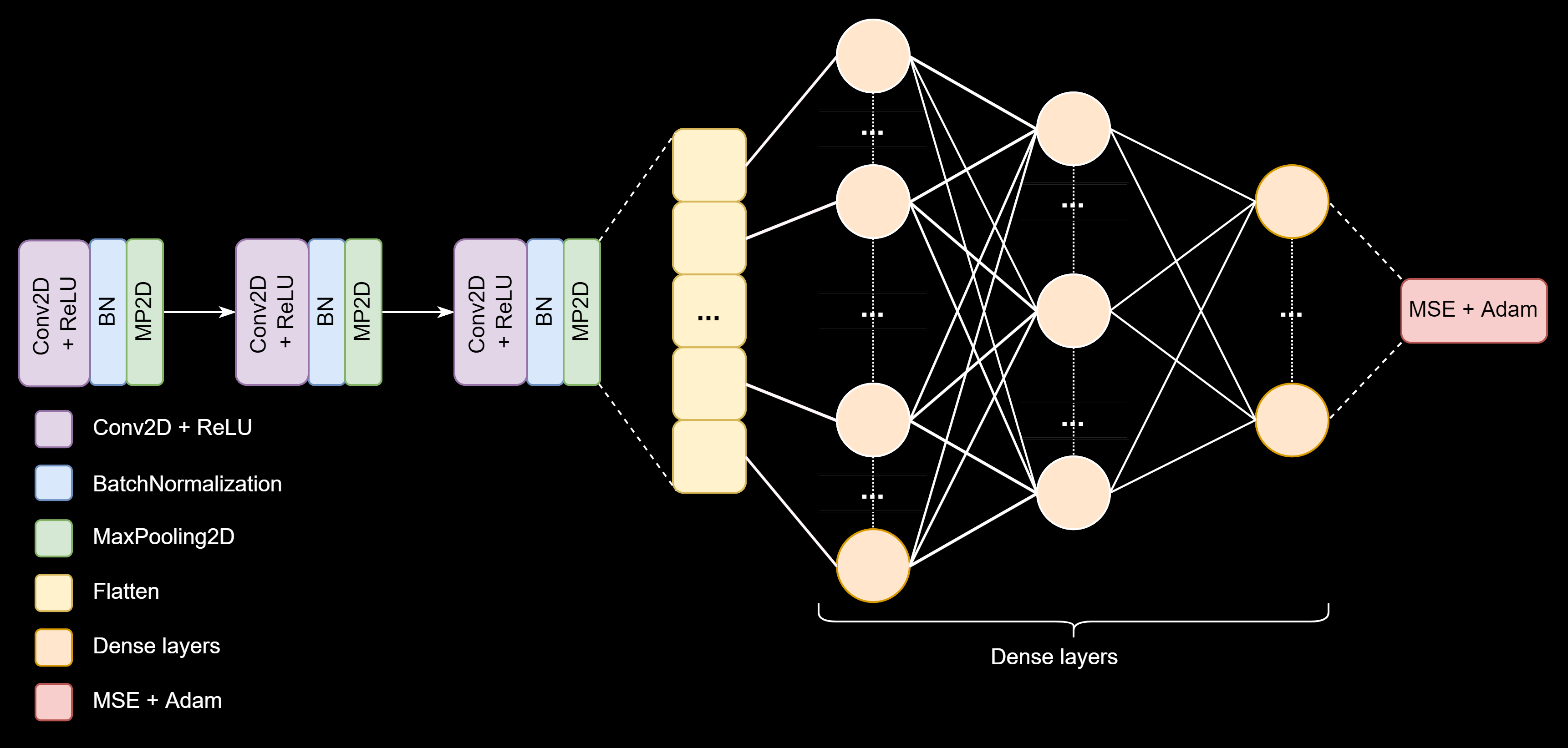
Training of a Deep Q-Network
The first step in training is to create a loop that only stops when the maximum number of driving attempts is reached. For each driving attempt, a state is also defined that indicates whether the car completed the route or collided. This is the done state and is set to False by default.
A second loop has been created that checks that the done state is not set to True. Then action is going to be performed for each image in the video stream. The exploration rate (epsilon ϵ) will decide whether this should be a random or predicted action. Then the agent receives the status and the belonging or punishment of the environment.
Finally, upon collision or exit, the done state is set to True and the rewards and punishments are stored in memory.
The final step in training is called Replay. This is the reintroduction of the experiences from the previous drive attempt into the algorithm and ensures more efficient use of previous experiences, by learning from them multiple times.
II. Literature study: Reinforcement Learning
Reinforcement Learning for Quick Autonomous Driving on Unknown Racetracks
Components of Autonomous Driving Systems
Perception of the environment
An autonomous car gathers relevant information from the environment using sensory perceptions. The main sense in an autonomous car is vision. The hardware involved is cameras and sensors (LiDAR, RADAR, GPS, etc.). The measurements from the hardware are used to perceive the environment. This is accomplished using obstacle or lane recognition, SLAM, etc.
"One characteristic common to all sensors is that they are susceptible to interference." [11] This can cause the observations from the sensors to not match reality or have significant noise. To avoid this and to interpret the sensory observations without error, a technique called sensor fusion is sometimes applied
"Sensor fusion combines sensory data to reduce uncertainty and help agents make more informed decisions." [11]
The system can make a plan to perfectly navigate the surroundings after the sensors have been combined.
Pathway planning & reasoning
A fully autonomous system, while receiving sensory observations from the environment, will have to make a decision on what is the safest and most efficient way to travel a route without colliding with the environment.
One possible solution to this is the A* algorithm (pronounced A-star). This is a popular algorithm that is widely used in computer science. The algorithm looks for the optimal and shortest path between certain points. "A* was [originally] invented by researchers working on the path planning of [a robot called] [...] 'Shakey' [...] and can be seen as an extension of Dijkstra's algorithm. The performance of A* is better [than the performance of Dijkstra's algorithm] because it uses heuristics [...]." [12]
From the moment a clear trajectory plan is developed, the RC car can be controlled.
Steering
A (simple) autonomous agent has, in the case of the internship elaboration and internship research, three types of actions. Namely, an agent must accelerate, decelerate, or adjust based on trajectory planning which, in turn, is derived from sensory perceptions. The environmental measurements can also always be exchanged with measurements from a simulation so that the autonomous system can navigate both virtually and in real life.
In more complex autonomous systems, such as self-driving cars, much more obviously needs to be considered.
Conclusion Autonomous Driving
The focus of an autonomous driving car is that based on the sensory observations, the environment is mapped and what is going on in the environment is understood. A plan is developed during the environmental measurements to drive as efficiently as possible.
The traditional computer vision implementation does not meet the above criteria. Sensory observations do take place but there is a lack of reasoning and planning from the car itself. The car does start driving 'independently' based on the environment but no trajectory planning is developed. Traditional computer vision still remains a hard-coded AI because the RC car literally applies the code to the environment and has no reasoning of its own to do so.
At this point in the research, there is a learning problem. Fortunately, the world of machine learning offers a solution to this. The domain within machine learning that focuses on training an algorithm through trial and error is reinforcement learning.
Wat is Reinforcement Learning?
The prediction models within the machine learning domain consist of three major pillars: supervised learning, unsupervised learning, and reinforcement learning.
Pillars of Machine Learning
Supervised learning or model learning has as input and output labeled data from a dataset. The model learns to predict an output based on similar input-output from a dataset. During training, feedback is provided on the predicted values. Based on this feedback, the model can adapt and make better predictions. It calls supervised learning because the process of training an algorithm based on a dataset can be seen as a teacher supervising and improving where needed. One possible implementation of supervised learning is a spam filter on a mailbox.
Unsupervised learning only has as input unlabeled data from a dataset. The goal of the model is to map the underlying structure in the dataset to learn more about the data. It is called unsupervised learning because, unlike supervised learning, there are no exactly correct executions and there is also no teacher or supervisor. The algorithms are allowed to discover the distribution in the data in their own way. One possible implementation of unsupervised learning is a recommendation system on a store's website or streaming service.
Semi-supervised learning exists too. This prediction model has not fully labeled data as input and is in between both worlds of supervised and unsupervised learning.
Finally, there is reinforcement learning. This is the domain within machine learning that applies operant conditioning instead of traditional input-output learning methods. The type of data to be predicted is also unknown in advance. Some possible implementations of reinforcement learning are self-driving cars or AI in games.
“In de gedragspsychologie is reinforcement een consequentie die het toekomstige gedrag van een organisme zal versterken wanneer dat gedrag wordt voorafgegaan door een specifieke stimulus.” [13]
Operant Conditioning

Operant conditioning is the learning process by which a behavior is modified by reward or punishment. [13] A very famous example of operant conditioning is the operant conditioning chamber or called Skinner box. The Skinner box is an experiment invented by Burrhus Frederic Skinner.
The experiment begins with a special box or crate in which an animal, usually a mouse or rat, is confined. The idea behind this conditioning chamber is reward and repeat or in English reward and repeat. This is because there are some stimuli in this room such as light, sound or smell, and a means or reinforcer, for example, water or food, which the animal is rewarded with. The reward can only be given to the animal as soon as it performs a certain action correctly. Some examples are pulling a lever on a green light or pushing a button on a red light. [13]
First, there are positive reinforcement and negative reinforcement. Positive reinforcement means that a reward is given when performing an action. This action will then become more common. This is, in short, what Edward Thorndike's Law of Effect is all about. Negative reinforcement is the removal of an unpleasant stimulus and thus will also make the action more frequent.
Then (positive) punishment and negative reinforcement follow. Positive punishment is a confusing term and is therefore usually referred to as just punishment or punishment. (Positive) punishment is when an unpleasant or unpleasant stimulus happens, for example, playing loud noises. Negative punishment is the removal of a (good) stimulus. Both methods of punishment cause a reduction in behavior.
Finally, there is extinction or extinction. Extinction occurs when a trained behavior is no longer effective. For example, when it no longer gets food by pressing the button, the animal gradually starts to press the button less and less and may look for other ways to get food. [13]
State, Action, Reward
Within a reinforcement learning algorithm, three things are defined: the states or states, actions, and rewards or rewards. States are a representation of the environment or the state of an environment at a given task. Actions are possible actions that an RL agent can do to change the states or states. The reward is the incentive mechanism that makes the agent perform tasks. Based on the reward, operant conditioning is applied. The main terms in reinforcement learning are explained in the table below.
| Term | Meaning | | ------------- | -------------- | | Agent | The robot whose actions are conditioned | | Environment | The circumstance in which the agent is | | State | The current situation of an environment | | Reward | The environment's response to an action | | Policy | The strategy the agent uses when performing an action | | Value | The possible reward for an action | | Value function | Assessing the potential reward in an action | | Model | Teaching indirect behaviors using an environmental model |
The initial states are the environment state and agent state. The environment status or environment state is what state the environment is in and what possible rewards/punishments there are. The agent state contains all possible decisions that an agent can make. The agent is always going to perform an action based on the environment state on which the environment can give a reward or staff and the agent can adjust itself. [13]
Reinforcement learning applies operant conditioning to agents that perform actions in an environment to maximize their reward.
The implementation of this in the internship task is as follows. The environment state is the location of the race track. The agent state is the RC car that can choose from the possible control options to accelerate, decelerate, or steer in a direction. A reward is given when the RC car, in the correct direction, completes the race track. A possible punishment would happen if the car hits the edge of the race track or starts driving in the wrong direction.
Methodologies within Reinforcement Learning
The problem with reinforcement learning is that when an agent is about to perform an action, there is no immediate clarity as to what state the agent is currently in or will be in. This is because the environment affects the agent. There are a number of possible solutions to this problem, namely: policy-based, value-based, and model-based reinforcement learning.
Policy- & Value-based RL (model-free)
In value-based implementations, also called value-based, a value function is used. This function tells the agent what the expected sum of all rewards is based on a state and action. No direct strategy is used but the next action can be derived directly from the value function by choosing the action with the best value.
In policy-based implementations, also called policy-based, instead of learning from a value function, the agent learns based on a strategy that associates a state with an action. The strategy is kept in memory while learning and can always be retrieved when a particular state reappears in the environment. [14]
There is a combination of value-based and policy-based implementations called actor-critic. This algorithm will develop and store a strategy based on a value function. Because it uses two other implementations, actor-critic is not included in any possible approach within this research.
The previous two taxonomies (value-based and policy-based) are components of model-free reinforcement learning. This means that no model of the environment needs to be developed. They rely on real examples from the environment and never use generated predictions of the next state. Data is collected from experiences that then lead to an optimal strategy or value function. In the next section, two implementations of model-free algorithms are examined. Following this, in section 3.2 Model-based reinforcement learning, the opposite is examined.
Q-Learning
The fundamental part of Q-learning is to create a table where the rows represent all possible states and where the columns are all possible actions. First, all values in the table are initialized with the value zero. Thanks to the exploration period of the agent, the table will already be partially filled with values. The higher the Q value, the better the choice of the corresponding action.
After an action of the agent, a value called the Q-value is calculated and filled in the table. The formula or value function for calculating the Q value is shown and explained below.
FORMULE Q-VALUE
Q(s, a) is the new Q value in the Q table. R(s, a) means the reward based on a state s and action a. Here the best Q-value based on the new state (s') and the previous action (a) is added up. After the training process within Q-Learning, the table will have a Q-value for each state and so the agent will know what to do in each known situation.
In the previous years' research on reinforcement learning, it was concluded that the Q-tables can become very large. In fact, the Q-table of the last training iteration was seven gigabytes in size. This is a problem because this cannot be read in by the RC car. [15] Thanks to this conclusion of the previous research, the decision was made to focus more on the neural network implementation during the current research.
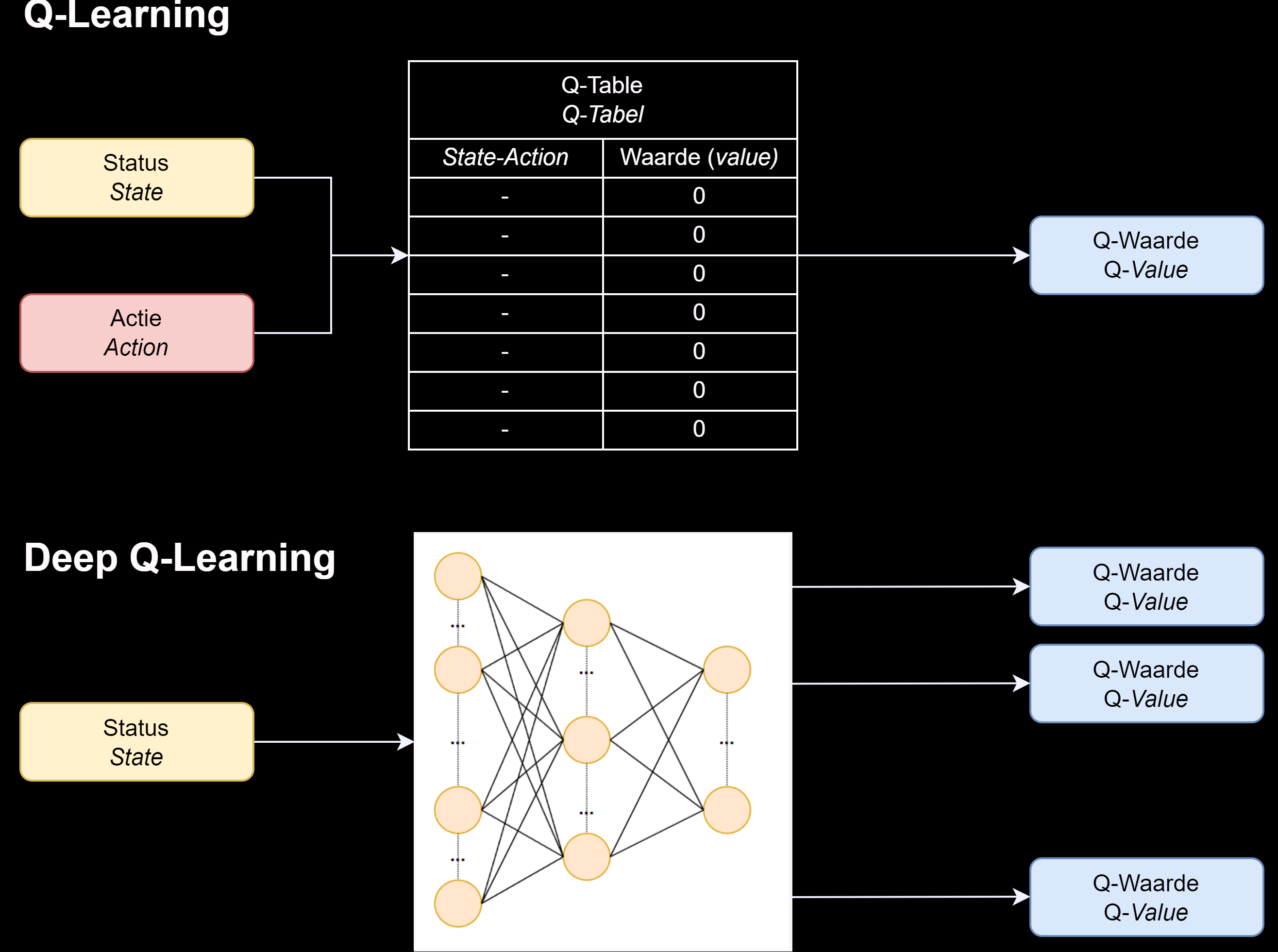
Deep Q-Learning
In Deep Q-Networks, a neural network is used to calculate the Q-value function. The state is the only input to the neural network and the Q-value is calculated for all possible actions as the output.
The implementation of a Deep Q-Learning algorithm also includes a replay step, also called experience replay or experience replay. This involves taking a small sample from the data of each past driving attempt to better train the neural network. Although Deep Q-Learning strongly resembles a model-based algorithm because it can take states and rewards from experience memory, it is still not a model-based algorithm.
Model-based RL
Model-based reinforcement learning, contrary to what the name suggests, does not need to use a neural network as a learning model. It can be used but is not necessary to speak of model-based reinforcement learning. Instead, the term refers strictly to whether the agent uses predictions from the environmental response during learning and stores a model of this.
Comparison Matrix
The table below compares the most important things from both algorithms. It can be deduced that Deep Q-Learning is a better application for the Race to the Future stage elaboration because it has to process imagery and does not require large storage.
| | Q-Learning | Deep Q-Learning |
| ------------- | -------------- | -------------- |
| Model-based? | No | No |
| Based on a value function? | Yes | Yes |
| Uses a table to store predictions? | Yes | No |
| Uses neural network | No | Yes |
| Can process large datastructures (images/videos) | Yes (but the Q-Tabel becomes enormous) | Yes, easily with a CNN |
Conclusion
The research is aimed at identifying the possibilities of reinforcement learning within autonomous driving. As a result, research was first conducted on what autonomous driving actually entails and then on the different methodologies under the domain of reinforcement learning.
The focus of an autonomous driving car is that based on sensory perceptions the environment is mapped and it understands what is happening in the environment. A plan is developed during the environmental measurements to drive as efficiently as possible. The traditional computer vision implementation does not meet the above criteria. Sensory observations do take place but there is a lack of reasoning and planning from the car itself. The car does start driving 'independently' based on the environment but no trajectory planning is developed. Traditional computer vision still remains a hard-coded AI because the RC car literally applies the code to the environment and has no reasoning of its own to do so. At this point in the research, there is a learning problem. Fortunately, the world of machine learning offers a solution to this.
The domain within machine learning that focuses on training an algorithm through trial and error is reinforcement learning. This domain applies operant conditioning instead of traditional input-output learning methods. Operant conditioning is the learning process by which a behavior is modified by reward or punishment. The problem with reinforcement learning is that when an agent is about to perform an action, there is no immediate clarity as to what state the agent is currently in or will be in. This is because the environment influences the agent. There are a number of possible solutions to this problem, namely: policy-based, value-based, and model-based reinforcement learning. These solutions were discussed and the value-based solution was also implemented in the simulation environment. From the research on reinforcement learning, it can be deduced that Deep Q-Learning is the best solution for the Race to the Future internship task because it has to handle large imagery and does not require large storage.
From the internship team, there are some challenges and possibilities for the future within the framework of autonomous driving and reinforcement learning. For example, the possibility of parallelism within reinforcement learning could be explored. This is a best practice in RL that looks at whether it is possible to train multiple RL agents simultaneously to speed up the learning process. Another possible suggestion for the future is to implement an improved version of the neural network. Possibly with more (or better) convolutional layers or a better optimization layer.
Reflection
INTRODUCTION
At the beginning of the internship assignment, the original intention was to implement both computer vision and reinforcement learning on the RC car and then have both algorithms run the race track. In the end, only computer vision was implemented on the car but with a simulation and literature review on reinforcement learning
LEARNING
The things we learned during the internship elaboration and research are things we could never obtain during a school semester.
For the first time in the two semesters of AI & Robotics, we were able to work with a physical robot.
This was a very unique experience to use ROS, Docker, and also Python in the real world. It was also the first time for both of us to implement a reinforcement learning algorithm. Our (linear) algebra was also refreshed back thanks to the internship elaboration and research. For example, we had to find the right formula or equation to calculate the steering angle and rewards.
Moreover, we also learned to deal with stressful situations. For example, the week before the Race to the Future event, a lot went wrong. The control software could no longer connect to our user interface or the car's camera failed. Even on the day of the race, the car suddenly couldn't be controlled anymore. Despite these setbacks, which brought down the motivation, we worked extra hard and solutions were found.
We also appreciated each other's ideas and opinions. There are discussions in every group but that did not stop us. Our completed work would not be as it is today if only one of us had done the work. We did not feel anger or hatred towards each other's weaknesses but gave each other a helping hand.
Last, we always respected our time and schedule tremendously. Thus, we always knew in time whether something was feasible or not. This is also why we made the decision to use only computer vision for the race and to keep reinforcement learning for after.
CONCLUSION
I can now look back and realize that this experience has helped me both as a student and as a young professional. Research and writing skills are not only valued in an academic setting, but also in the computer science industry.
I am now much more confident in my writing and research skills. In addition, working under a supervising lecturer has given me the opportunity to develop a mentor/mentee relationship with a professional in the computer science industry. Overall, I feel that this has been a valuable experience and I now feel prepared for my upcoming academic and career years.
References
-
Race to the Future organization, „Race to the future Reglement,” 2020. [Online]. Available: https://www.racetothefuture.be/couch/uploads/file/rttf_reglement_2020.pdf.
-
Wikipedia, „Computer vision,” Wikipedia, 09 04 2022. [Online]. Available: https://en.wikipedia.org/wiki/Computer_vision.
-
Wikipedia, „Bilateral filter,” Wikipedia, 18 03 2022. [Online]. Available: https://en.wikipedia.org/wiki/Bilateral_filter.
-
Wikipedia, „CIELAB color space,” Wikipedia, 2022 03 16. [Online]. Available: https://en.wikipedia.org/wiki/CIELAB_color_space.
-
NumPy Developers, „NumPy.bitwise_or,” NumPy, 01 05 2022. [Online]. Available: https://numpy.org/doc/stable/reference/generated/numpy.bitwise_or.html#numpy-bitwise-or.
-
Wikipedia, „Bézier curve,” Wikipedia, 21 04 2022. [Online]. Available: https://en.wikipedia.org/wiki/Bézier_curve.
-
S. Lague, „Bézier Path Creator,” Unity Asset Store, 26 06 2019. [Online]. Available: https://assetstore.unity.com/packages/tools/utilities/b-zier-path-creator-136082.
-
OpenAI, „Gym Documentation,” OpenAI, 2022. [Online]. Available: https://www.gymlibrary.ml/.
-
Y. Yaseq, „DQN with Decaying Epsilon (Answer),” Data Science Stack Exchange, 09 09 2020. [Online]. Available: https://datascience.stackexchange.com/questions/81438/dqn-with-decaying-epsilon.
-
K. C. A. H. Hao Yi Ong, „Distributed Deep Q-Learning,” 18 08 2015. [Online]. Available: https://doi.org/10.48550/arXiv.1508.04186.
-
Udacity Team, „How Sensor Fusion Works,” Udacity, 11 01 2021. [Online]. Available: https://www.udacity.com/blog/2021/01/how-sensor-fusion-works.html.
-
Wikipedia, „A* search algorithm,” Wikipedia, 12 04 2022. [Online]. Available: https://en.wikipedia.org/wiki/A*_search_algorithm.
-
PXL AI & Robotics Lab, „Robotics Advanced Course Materials 21-22,” PXL-Digital, 17 09 2021. [Online]. Available: https://github.com/PXLAIRobotics/RACourseMaterialsForStudentsGen3.
-
T. Simonini, „An introduction to Policy Gradients with Cartpole and Doom,” freeCodeCamp.org, 09 05 2018. [Online]. Available: https://www.freecodecamp.org/news/an-introduction-to-policy-gradients-with-cartpole-and-doom-495b5ef2207f/.
-
Y. D'hulst, „Reinforcement learning toepassen op autonome voertuigen,” PXL-Digital, Hasselt, 2021.
-
Wikipedia, „Convolutional neural network,” Wikipedia, 07 06 2022. [Online]. Available: https://en.wikipedia.org/wiki/Convolutional_neural_network#Deep_Q-networks.